




چگونه هوش مصنوعی Bias روی تشخیص پزشکی تاثیر می گذارد؟
مدلهای هوش مصنوعی که در پیشبینی نژاد/جنس خوب هستند، دقت کمتری در تشخیص دارند.

به گزارش علمی نیوز و به نقل از Psychology Today، درست مانند انسانها، مدلهای یادگیری ماشینی هوش مصنوعی (AI) مستعد سوگیری هستند. درک ماهیت سوگیری هوش مصنوعی برای کاربردهای حیاتی که ممکن است بر تصمیمات مرگ یا زندگی تأثیر بگذارد، مانند صنایع پزشکی و مراقبت های بهداشتی، بسیار مهم است. تحقیقات جدید منتشر شده در Nature Medicine نه تنها نشان میدهد که مدلهای تصویربرداری پزشکی هوش مصنوعی که در پیشبینی نژاد و جنسیت عالی هستند، در پیشبینی تشخیص بیماری به خوبی عمل نمیکنند، بلکه بهترین شیوهها را برای رفع این نابرابری ارائه میکنند.
مرضیه قاسمی، نویسنده ارشد، دانشیار مهندسی برق و علوم کامپیوتر، مینویسد: «یافتههای ما بر ضرورت ارزیابی منظم عملکرد مدل تحت تغییر توزیع تأکید میکند، و دیدگاه عمومی یک مدل منصفانه را در تنظیمات مختلف به چالش میکشد». در موسسه فناوری ماساچوست (MIT)، با همکاری دینا کاتبی، دکتری، استاد علوم کامپیوتر و مهندسی برق در MIT، یوژه یانگ، دانشجوی کارشناسی ارشد MIT CSAIL، هاوران ژانگ، دانشجوی کارشناسی ارشد MIT، و جودی Gichoya، Ph.D.، دانشیار رادیولوژی در دانشکده پزشکی دانشگاه اموری.
استفاده از یادگیری ماشینی هوش مصنوعی در تصویربرداری پزشکی در حال رشد است. بر اساس گزارش صنعت گراند ویو ریسرچ، انتظار میرود اندازه بازار هوش مصنوعی در تصویربرداری پزشکی تا سال 2030 در سطح جهان به 8.18 میلیارد دلار برسد، با نرخ رشد مرکب سالانه 34.8 درصد طی سالهای 2023-2030. براساس تحقیقات گراند ویو، استفاده از هوش مصنوعی در مغز و اعصاب، با 38.3 درصد سهم، بزرگترین بخش بود و منطقه آمریکای شمالی در سال 2022 سهم درآمدی 44 درصدی داشت. نمونههایی از شرکتهای موجود در فضای تصویربرداری پزشکی هوش مصنوعی عبارتند از IBM، GE Healthcare، Aidoc، Arterys، Enlitic، iCAD Inc.، Caption Health، Gleamer، Fujifilm Holdings Corporation، Butterfly Network، AZmed، Siemens Healthineers، Koninklijke Philips، Agfa-Gevaert Group/ Agfa Health Care، Imagia Cybernetics Inc.، Lunit، ContextVision AB، Blackford Analysis و دیگران.
ظهور استفاده از هوش مصنوعی در تصویربرداری پزشکی مستلزم به حداکثر رساندن دقت و به حداقل رساندن سوگیری ها است. اصطلاح سوگیری شامل جانبداری، گرایش، ترجیح و الگوهای تفکر سیستماتیک ناقص است. در افراد، سوگیری ها می تواند آگاهانه یا ناخودآگاه باشد. تعصبات انسانی متعددی وجود دارد. نمونهها عبارتند از کلیشهسازی، اثر باند واگن، اثر دارونما، سوگیری تایید، اثر هاله، خوشبینی، سوگیری پسبینی، سوگیری لنگر، اکتشافی در دسترس، سوگیری بقا، سوگیری آشنایی، سوگیری جنسیتی، مغالطه قمارباز، خطای اسناد گروهی، سوگیری خود انتساب ، و خیلی بیشتر.
تعصب هوش مصنوعی بر دقت عملکرد کلی تأثیر می گذارد. در یادگیری ماشینی هوش مصنوعی، الگوریتمها از مقادیر انبوه دادههای آموزشی یاد میگیرند تا دستورالعملهای سخت کدگذاری شده صریح. عوامل متعددی بر انعطافپذیری مدلهای هوش مصنوعی در برابر سوگیری تأثیر میگذارند. اینها نه تنها شامل کمیت داده های آموزشی، بلکه کیفیتی است که تحت تأثیر سطح عینی بودن داده ها، خود ساختار داده، شیوه های جمع آوری داده ها و منابع داده قرار می گیرد.
علاوه بر این، مدلهای هوش مصنوعی ممکن است در برابر سوگیریهای شناختی ذاتی انسانهایی که مسئول ایجاد الگوریتم، وزنهای اختصاص دادهشده به نقاط داده، و نبود یا گنجاندن شاخصها هستند، آسیبپذیر باشند. به عنوان مثال، در فوریه 2024، گوگل تصمیم گرفت تولید تصویر ربات چت هوش مصنوعی Gemini (بارد سابق) را پس از شکایت کاربران مبنی بر ایجاد تصاویر نادرست تاریخی متوقف کند. یعنی، Gemini تمایل داشت که از تولید تصاویر افراد غیرسفید پوست حمایت کند و اغلب به اشتباه با نژاد و/یا جنسیت اشتباه نشان داده می شد. به عنوان مثال، قبل از مکث، جمینی به اشتباه جورج واشنگتن و وایکینگ ها را به عنوان مردان سیاه پوست به تصویر کشید. گوگل تنظیم دقیق مولد تصویر خود به نام Imagen 2 را نسبت داد که در نهایت باعث شد مدل هوش مصنوعی در یک پست وبلاگ شرکتی به هم بخورد.

محققان MIT گزارش دادند: "ما تایید می کنیم که هوش مصنوعی تصویربرداری پزشکی از میانبرهای جمعیتی در طبقه بندی بیماری ها استفاده می کند."
این تعجب آور نبود، زیرا دو سال قبل، قاسمی، گیچویا و ژانگ از جمله نویسندگان یک مطالعه جداگانه MIT و دانشکده پزشکی هاروارد بودند که در The Lancet Digital Health منتشر شد و نشان داد که چگونه مدلهای یادگیری عمیق هوش مصنوعی میتوانند خودآگاهی فرد را پیشبینی کنند. نژاد از داده های پیکسل تصویر پزشکی را به عنوان ورودی با درجه بالایی از دقت گزارش کرد. مطالعه سال 2022 نشان داد که هوش مصنوعی به راحتی یاد گرفت که هویت نژادی خود را از تصاویر پزشکی تشخیص دهد. با این حال، انسانها نمیدانند که هوش مصنوعی چگونه به این امر دست مییابد، بنابراین بر نیاز به کاهش خطر با ممیزیها و ارزیابیهای منظم هوش مصنوعی پزشکی تأکید میکند.
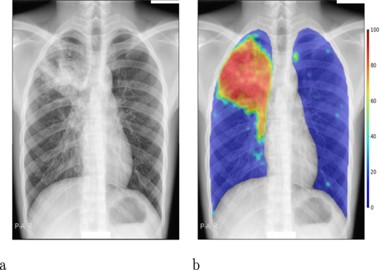
برای مطالعه کنونی، هدف دانشمندان تعیین این بود که آیا مدلهای طبقهبندی بیماری هوش مصنوعی از اطلاعات جمعیتشناختی به عنوان یک اکتشافی استفاده میکنند و آیا این میانبرها باعث پیشبینیهای جانبدارانه میشوند. مدلهای هوش مصنوعی برای پیشبینی اینکه آیا بیمار دارای یکی از سه وضعیت پزشکی است یا خیر، آموزش دیدهاند: سقوط ریه، بزرگ شدن قلب، یا تجمع مایع در ریهها.
مدلهای هوش مصنوعی بر روی اشعه ایکس قفسه سینه از مجموعه دادههای عمومی موجود از رادیوگرافی قفسه سینه از مرکز پزشکی Beth Israel Deaconess در بوستون به نام MIMIC-CXR آموزش دیدند و سپس بر روی یک مجموعه داده ترکیبی خارج از توزیع متشکل از دادههای CheXpert، NIH ارزیابی شدند. ، SIIM، PadChest و VinDr. در علم داده، دادههای خارج از توزیع (OOD) دادههای جدیدی هستند که مدل هوش مصنوعی بر روی آنها آموزش ندیده است و بنابراین، برخلاف دادههای درون توزیع (ID) که مدل هوش مصنوعی دارد، «غیره» در نظر گرفته میشود. قبلاً در داده های آموزشی دیده شده است. به طور کلی، محققان از بیش از 854000 اشعه ایکس قفسه سینه از مجموعه دادههای رادیولوژی با منبع جهانی که در سه قاره، 6800 تصویر چشم پزشکی و بیش از 32000 تصویر پوست استفاده میشوند، استفاده کردند.
مدلهای هوش مصنوعی به طور کلی در پیشبینیهای خود خوب عمل کردند، اما تفاوتهایی در دقت پیشبینی بین جنسیت و نژاد نشان دادند. مدلهای هوش مصنوعی که بهترین عملکرد را در پیشبینی جمعیتشناختی داشتند، تفاوتهای بیشتری را در دقت تشخیص تصاویر جنسیتها یا نژادهای مختلف نشان دادند.
در مرحله بعد، این تیم بررسی کرد که چگونه تکنیکهای پیشرفته و مؤثر میتوانند این میانبرها را برای ایجاد مدلهای هوش مصنوعی کاهش دهند که سوگیری کمتری دارند. آنها دریافتند که می توانند اختلاف سناریوها را برای کاهش تعصبات کاهش دهند. با این حال، این روشها زمانی مؤثرتر بودند که مدل بر روی همان نوع بیمارانی که هوش مصنوعی در ابتدا روی آنها آموزش دیده بود، یا به عبارت دیگر، با دادههای درون توزیع ارزیابی شد.
در یک محیط بالینی در دنیای واقعی، آموزش مدلهای هوش مصنوعی بر روی دادههایی که خارج از توزیع از یک بیمارستان دیگر هستند، غیرعادی نیست. به عنوان بهترین روش، این تحقیق نشان میدهد که بیمارستانهایی که از مدلهای هوش مصنوعی توسعهیافته با دادههای بیرونی و خارج از توزیع استفاده میکنند، باید الگوریتمهای دادههای بیمار خود را به دقت ارزیابی کنند تا دقت عملکرد را در میان جمعیتشناسی مختلف مانند نژاد و جنسیت درک کنند.
محققان نتیجه گرفتند: «این کارآیی تضمینهای توسعهدهنده بر عدالت مدل در زمان آزمایش را زیر سوال میبرد و نیاز نهادهای نظارتی را برای در نظر گرفتن نظارت بر عملکرد در دنیای واقعی، از جمله تخریب انصاف، برجسته میکند».